:: Loss Function(손실함수)란? ::
간단히 말해 모델이 얼마나 좋은지 / 나쁜지를 정량화하는 함수이다.
loss(손실)이 작을수록 더 좋은 모델이기 때문에 딥러닝 학습의 최종 목표는 loss값을 최소화하는 (가중치를 찾는)것이다.
:: Loss Function의 종류 ::
- 이진 분류에 이용되는 loss function
- Discriminative Setting
y_hat > 0 : positive class , y_hat < 0 : negative class
loss : y*y_hat에 의해 정의
- y와 y_hat의 부호가 같다면(예측 성공) -- y*y_hat > 0 -- loss값 작아짐
- y와 y_hat의 부호가 다르다면(예측 실패) -- y*y_hat < 0 -- loss값 커짐
1) 0/1 loss

0/1 loss는 간단하게 y*y_hat이 양수라면 loss값이 0이 되고, y*y_hat 값이 음수라면 loss값이 1이 되는 함수이다.
(가로축과 세로축이 각각 y*y_hat, loss라는 점 주의)
하지만, loss가 0이냐 1이냐를 가르는 부분에서 미분이 불가능하다는 단점이 있고 모델이 정답을 거의 예측하지 못했을 때 (y와 y_hat의 차이가 클 때)에도 loss를 1밖에 줄 수 없다는 단점이 있다.
2) log loss

반면 log loss는 모든 순간에서 미분이 가능하고,
모델이 정답을 예측하지 못했을 경우 loss를 크게 줄 수 있다.
- 하지만 이런 점이 outlier에 취약하게 만드므로 노이즈가 많은 데이터에는 적합하지 않다!
3) exponential loss

exponential loss 역시 모든 순간에서 미분이 가능하고
log loss에 비해 loss값이 더 커진 것을 볼 수 있다.
4) hinge loss

hinge loss는 미분 불가능한 점이 존재하지만 중요한 순간이 아니므로 모델 학습에 큰 영향을 미치지 않고,
표시된 부분을 보면 아슬아슬하게 예측에 성공한 부분에 대해서도 어느 정도 페널티를 줄 수 있는 것을 볼 수 있다.
- 서포트 벡터 머신(SVM)에서 사용됨!
- 다중 분류에 이용되는 loss function
다중 분류에서 정답은 y = {0, 0, ..., 1, 0, 0}과 같은 벡터 형태(이런 형태를 one-hot 인코딩 벡터라고 함)를 가진다.
1) Cross Entropy

- N : 데이터 샘플의 수 개수
- K : 클래스의 개수
- y_ik : 정답(샘플 i의 실제 클래스에 대한 one-hot 인코딩 벡터의 k 번째 요소)
(실제 레이블의 i번째 샘플에 대한 실제 label이 k번째 class가 맞으면 1, 틀렸으면 0)
- (y_ik )_hat : 예측값(모델이 i번째 샘플에 대해 예측한 class k의 확률)
- Cross Entropy가 이진 분류에 사용된다면?

> k = 2 로 설정함으로써 간단하게 표현 가능
>> 모든 class의 정답(y_i), 예측 값((y_i)_hat)의 합은 1이므로 ㅁ, 1-ㅁ 로 표현할 수 있음!
- Cross Entropy가 왜 로스 함수로 사용될 수 있을까?
다중 분류에서 정답은 y_ik = {0, 0, 0, 1, 0, 0} 처럼 하나의 값만 1, 나머지는 모두 0인 벡터이다.
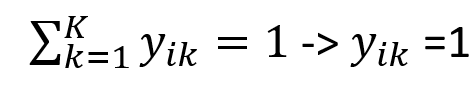
따라서 왼쪽 그림과 같은 경우
(해당 데이터가 k번째 클래스에 속하는 경우)에만 식을 계산하면 된다.
**식이 잘 이해되지 않아서 추가 설명
y_ik는 실제 레이블의 i번째 샘플에 대해 실제 label이 k번째 class가 맞으면 1, 틀렸으면 0의 값을 가짐.
간단하게 k = 3인 상황을 보자.
y_i = {0, 1, 0} & (y_i)_hat = {0.1, 0.8, 0.1} 이라고 한다면 cross entropy 식은∑(i = 1에서 N까지) (0 x log(0.1) + 1 x log(0.8) + 0 x log(0.1)) = ∑(i = 1에서 N까지) 1 x log(0.8) 와 같아진다. 즉, 정답을 맞춘 경우에만 식을 계산하면 된다는 것!
따라서 최종 식을

과 같이 정리할 수 있게 된다.
- log 앞에 (-)가 붙는 이유
y_hat(y_i_T_i_hat...이지만 간단하게 표현하기 위해 y_hat으로 표기하겠음)은 확률 값으로 모두 0과 1 사이 값을 가진다.
우리는 앞서 말했듯이, loss function는 정답에 가깝게 예측할 수록 loss값을 작게, 정답을 맞추지 못할수록 loss값을 크게 설정하고자 한다.
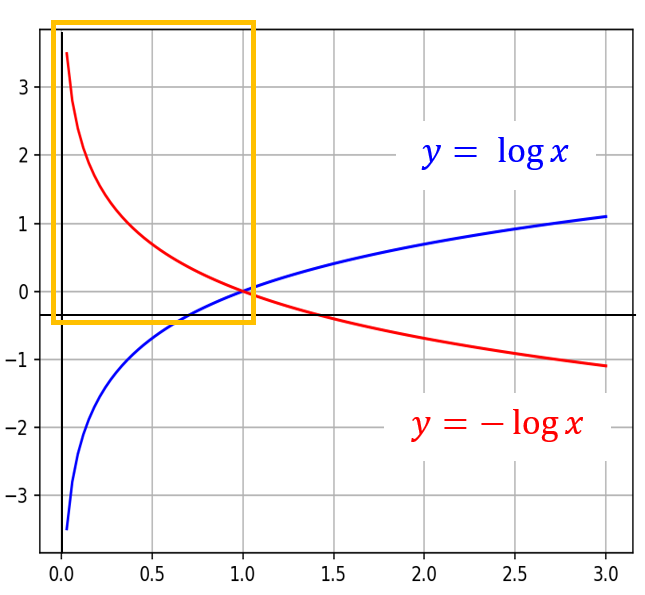
옆의 y = -log(x) 함수를 보면
x가 1에 가까워질수록 y는 0에 가까워짐
<-> 정답이 1인 class에 대해 모델이 정확하게 1이라고 예측
>> 로스 함수의 결과(y)( = 페널티)는 0에 가까워짐
x가 0에 가까워질수록 y는 양의 무한대로 발산
<-> 정답이 1인 class에 대해 모델이 0으로 잘못 예측
>> 로스 함수의 결과(y)( = 페널티)는 커짐
이때까지 위에서 설명한 cross entropy 식은 엄밀하게 말하면 Categorical Cross-Entropy(실제 클래스와 예측 확률 분포 간의 차이를 계산하는 함수)이다.
2) Sparse Categorical Cross Entropy(SCCE)
SCCE는 Categorical Cross Entropy와는 달리 정답(label)이 정수형 클래스 인덱스(ex) 0, 1, 2,..)로 주어진다.
(> one-hot 인코딩 벡터 형식이 아님.)
기본적으로 데이터 셋이 제공될 때 label이 정수 형태를 띄고 있는 경우가 많은데, 이런 경우 SCCE를 이용한다.
SCCE의 식도 Categorical Cross Entropy와 유사한 형태인데,

- y_i : i번째 샘플의 실제 클래스 인덱스
- 노란색 부분(전체가 변수 하나) : 해당 클래스에 대한 모델의 예측 확률
class가 상호 배타적일 때(exclusive 할 때 = 각 샘플이 정확히 하나의 class에 속하는 경우) >> Sparse Categorical Cross Entropy 이용
하나의 여러 class를 가질 수 있거나 label이 소프트 확률(ex) {0.5, 0.3, 0.2})일 때 >> Categorical Cross Entropy 이
이렇게 두 가지 경우에 나누어 이용할 수 있지만, 공식이 동일하므로 정확도에는 영향이 없다고 한다.
- 회귀에 이용되는 loss function
1) Mean Squared Error(MSE)
평균제곱오차라고도 불리는 MSE는 이름에서 알 수 있듯이 정답과 예측값의 차이의 제곱의 평균를 나타내는 함수이다.

정답과 예측값'의' 차이'의' 제곱'의' 평균 이라니..쓰고 보니 문장으로 설명하면 굉장히 어려워 보인다.
조금 더 직관적으로 설명해보자면, 정답과 예측값의 거리의 제곱의 평균이다.
우리는 모델이 예측을 더 잘 하길 원하고, 이는 곧 정답과 예측값 사이의 거리가 작기를 원한다.
앞서 말했던 정답에 가깝게 예측하면 페널티를 적게 주고, 정답에 맞지 않으면 페널티를 많이 주는 로스 함수의 원리와 일치하는 것이다.
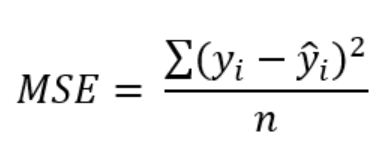
- y_i : 정답 값
- y_i_hat : 예측 값
- (y_i - y_i_hat)^2 : 정답 값과 예측값의 차이의 제곱 = 정답과 예측값 사이 거리의 제곱
- n : 샘플의 개수
- 왜 거리의 '제곱'일까?
간단하게 생각해볼 수 있다.
우리가 원하는 것은 정답과 예측값이 얼마나 떨어져 있는지를 숫자로 표현하기를 원한다.
예를 들어 정답이 {1, 5} 이고 모델이 정답을 {3,3}으로 예측했다고 가정해보자.
제곱 없이 정답과 예측값 사이의 차를 이용해서 식을 계산한다면,
{(1-3) + (5-3)} / 2 = {(-2) + 2) / 2 = 0 / 2 = 0
으로 잘 예측했다고 판단할 수 있다.
따라서 상쇄되는 값을 방지하기 위해 제곱을 하는 것이다.
> MAE도 마찬가지!
추가로 알아두면 좋은 개념은 '잔차(Residual, 주로 e로 표기)'이다.
y_i - y_i_hat, 즉 정답에서 예측을 뺀 값을 잔차라고 한다.
따라서 MSE를 간단하게 말하면, 잔차의 제곱의 평균이 될 수 있다.
2) Mean Absolute Error(MAE)
MAE는 MSE와 이름처럼 유사하다.
차이점은, 정답과 예측값 사이의 '거리'를 계산하기 위하여 절댓값을 이용한다는 점!
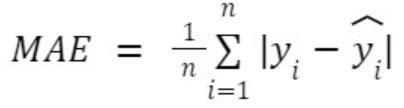
- y_i : 정답 값
- y_i_hat : 예측 값
- n : 샘플의 개수
이진 분류에 이용되는 loss function 중 exponential loss가 큰 loss 값을 주기 때문에 이상치에 민감하다고 언급했었다.
MSE와 MAE도 마찬가지로 MSE가 제곱을 계산하기 때문에 더 큰 값을 반환하고, MAE에 비해 이상치에 민감하다.
따라서 이상치가 많은 데이터에는 MSE보다 MAE를 이용하는 것이 더 좋다고 한다!
- 참고 링크
https://peterleeeeee.github.io/categorical_cross_entropy/
https://modulabs.co.kr/blog/machine_learning_loss_function/
https://statisticsbyjim.com/regression/mean-squared-error-mse/
https://www.youtube.com/watch?v=Bxyj5p1CAeg
'AI' 카테고리의 다른 글
| 이미지 데이터 증강 : CutMix (0) | 2024.09.19 |
|---|---|
| [논문 리뷰] Visible and Thermal Camera-based Jaywalking Estimation using a Hierarchical Deep Learning Framework (2) | 2024.09.12 |
| [LSFM] 논문 기초 준비 (2) | 2024.09.05 |
| Optimizer_SGD (0) | 2024.08.29 |
| VGGNet의 구조(+CNN 기본 개념 정리) (2) | 2024.08.15 |



